
I used to be a web back-end developer. The first time, I saw code from a data scientist, I was shocked. For me it was a mess. The quality was poor in comparison of what I was used to doing in software development. There was almost no test. I was unpleasantly surprised to see that sometimes there was no versioning system.
Seeing that, I was sure: data scientists act crazy. Now, I am a data scientist. Do I act crazy? I hope not.
Yes, the level of code quality could be better in data science. Data quality is even more important
I’m not saying that code quality is not useful in data science. It is. But code is maybe less important than data in data science. First, it is rarely as huge and complex as that in software engineering. It doesn’t express functionalities.
In software development, you build a specification.
You create a program with data to get a result.
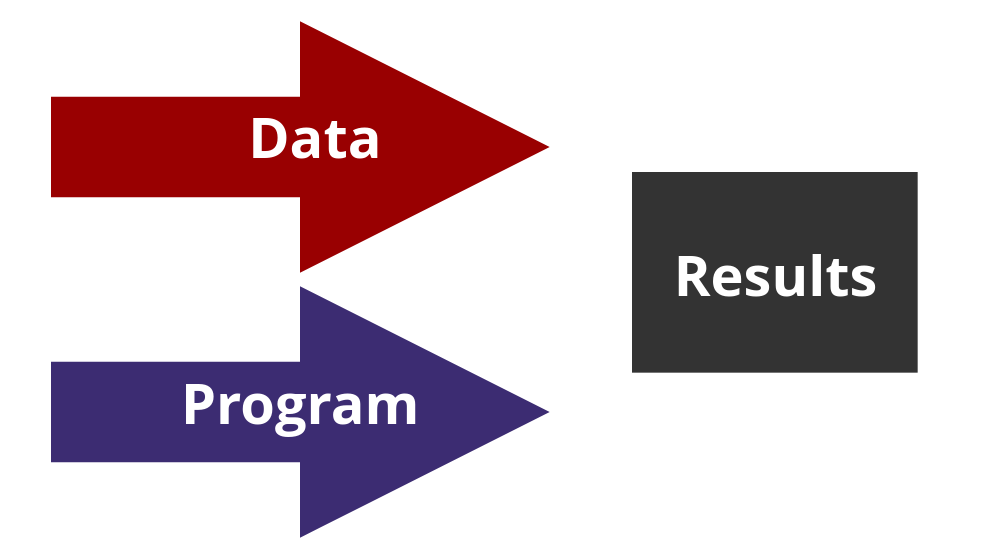
In data science, you try to optimize a cognitive process. You have some data and one result. With that, you build a program.
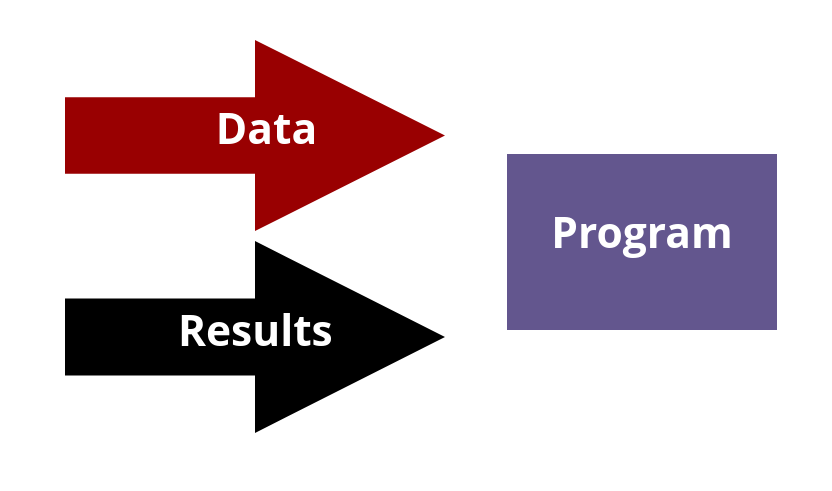
You have less code.
On the contrary, you have much more data. I have already seen projects stopped because of data quality. If you want to improve a process but have poor data about it, you won’t be able to build a system with that.
Then, as a data scientist, you need to pay attention to your code quality and your data quality.
Yes, data scientists could do more code tests. Data and model tests are even more important
Tests are important. They are the key if you want to be sure that your application is working. And you don’t want to do that manually. So, fortunately, automated tests were invented. And that’s nice.
And I definitely think that code tests are important in data science even if you have less code. It’s the way to be sure that you have no regression.
… At least not in your code.
In data science, regressions can come from your data and it can impact your model. If you don’t monitor it, you will have a silent failure. Your system has no visible bugs. But the prediction is inefficient.
To prevent that, you can test the performance of your model to be sure that everything is still okay.
You can also track your data quality and your data changes. If you have a broken data or a high variation in your data, your model can perform badly.
This is why testing your data and model is so important.
Yes, versioning your machine learning code is important. Versioning your model and you data is almost as much as important
I don’t think versioning your code is an option.
But, when your data are so important that they build your program, it’s important to version them too.
In case of a bug, you know what happened. By versioning your data and your model, which is stochastic, you can reproduce a previous state.
Conclusion
Don’t get me wrong. Code quality, code tests and code versioning are very important even in data science. I regret they are so often forgotten.
In data science, data is maybe more important than code. To my opinion, this is why sometimes data scientists are more willing to test and version their data and models than their code.
Data science is complex because to build a reliable system you must test, version and pay attention to the quality of your code, BUT ALSO your models and data.
To conclude, I would say that yes the first time, I saw code from a data scientist, I was shocked. Now as a machine learning engineer, I think code quality could be better in data science, but I realise the importance of models and data quality too. Code quality is only the tip of the iceberg.