
Data are the food of machine learning training. There are more and more data everyday. But most of the time, these data are unlabelled. Labelling them manually is expensive and boring.
There are different ways to tackle this problem.
Active learning
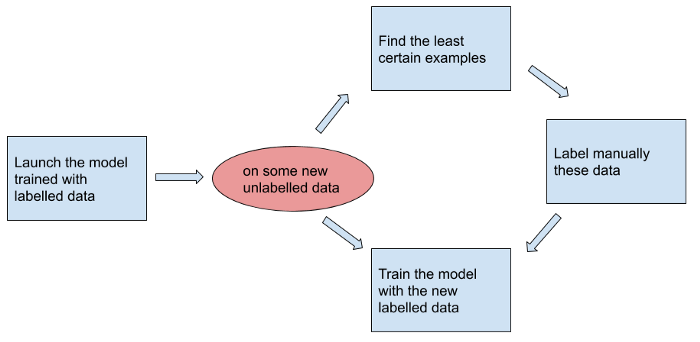
Active learning optimises labelling. It extracts the data that must be labelled.
The system requests a manual labelling for identified cases. Those depend on the strategy you choose. I will cover only two of these strategies.
Uncertainty sampling
When using a model, you get more or less certain results. The idea is to identify and label manually the least certain ones.
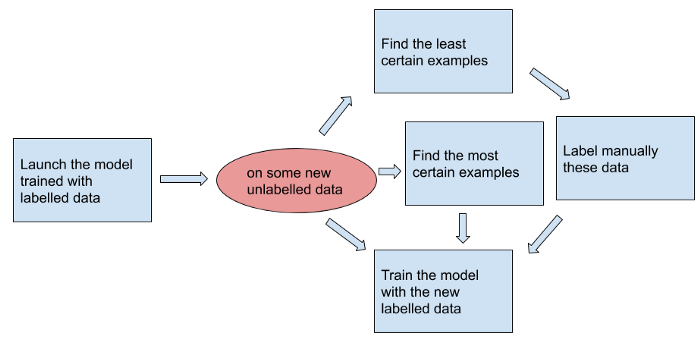
Semi-supervised learning
This method looks for the most certain examples too. It uses them as labelled data.
Links to go further:
Reinforcement learning
In reinforcement learning, you learn from experiences.
You have a target. An agent tries to reach it by performing actions. Its successes and failures train your model in the right direction.
One day, someone told me:
Reinforcement learning is a supervised learning with data. It just gets these data over the time. You can use reinforcement learning when interracting with an environment and limited data.
A tutorial to get started with reinforcement learning:
Data augmentation
From a same data, you can extract several others.
You can take a cat picture. You flip, crop, scale or rotate it. From one labelled picture, you now have four new labelled pictures.

A reading about data augmentation:
A small library for image augmentation:
Unsupervised learning
Labelling is a supervised learning problem. To tackle it, you can use unsupervised learning instead. This possibility depends on the problem you have.
Suppose you want to extract anomalies from an ensemble. A supervised learning could label some examples. Then, it trains the model.
Instead, you could cluster similar things together. Groups very different from the others could be anomalies.
It is a simple example. However, it is possible to imagine more complex solutions.
Conclusion
Labelling in machine learning is an issue. It is expensive and leads to boring tasks.
You can keep the costs of labelling down with automatic solutions. I wanted to highlight some methods to do that.